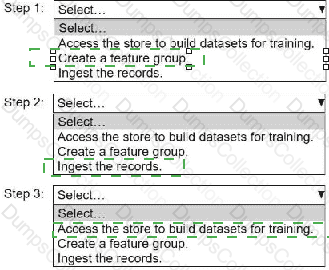
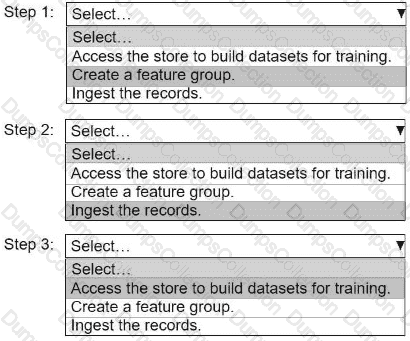
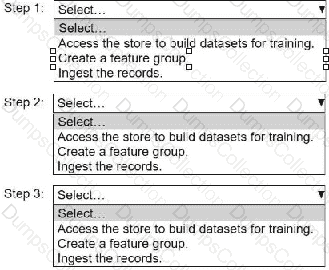
An ML engineer needs to use Amazon SageMaker Feature Store to create and manage features to train a model.
Select and order the steps from the following list to create and use the features in Feature Store. Each step should be selected one time. (Select and order three.)
• Access the store to build datasets for training.
• Create a feature group.
• Ingest the records.
An ML engineer is building a logistic regression model to predict customer churn for subscription services. The dataset contains two string variables: location and job_seniority_level.
The location variable has 3 distinct values, and the job_seniority_level variable has over 10 distinct values.
The ML engineer must perform preprocessing on the variables.
Which solution will meet this requirement?
A company uses an Amazon EMR cluster to run a data ingestion process for an ML model. An ML engineer notices that the processing time is increasing.
Which solution will reduce the processing time MOST cost-effectively?
A company uses a training job on Amazon SageMaker Al to train a neural network. The job first trains a model and then evaluates the model ' s performance ag
test dataset. The company uses the results from the evaluation phase to decide if the trained model will go to production.
The training phase takes too long. The company needs solutions that can shorten training time without decreasing the model ' s final performance.
Select the correct solutions from the following list to meet the requirements for each description. Select each solution one time or not at all. (Select THREE.)
. Change the epoch count.
. Choose an Amazon EC2 Spot Fleet.
· Change the batch size.
. Use early stopping on the training job.
· Use the SageMaker Al distributed data parallelism (SMDDP) library.
. Stop the training job.

A company collects customer data every day. The company stores the data as compressed files in an Amazon S3 bucket that is partitioned by date. Every month, analysts download the data, process the data to check the data quality, and then upload the data to Amazon QuickSight dashboards.
An ML engineer needs to implement a solution to automatically check the data quality before the data is sent to QuickSight.
Which solution will meet these requirements with the LEAST operational overhead?
A healthcare analytics company wants to segment patients into groups that have similar risk factors to develop personalized treatment plans. The company has a dataset that includes patient health records, medication history, and lifestyle changes. The company must identify the appropriate algorithm to determine the number of groups by using hyperparameters.
Which solution will meet these requirements?
A company is uploading thousands of PDF policy documents into Amazon S3 and Amazon Bedrock Knowledge Bases. Each document contains structured sections. Users often search for a small section but need the full section context. The company wants accurate section-level search with automatic context retrieval and minimal custom coding.
Which chunking strategy meets these requirements?
A government agency is conducting a national census to assess program needs by area and city. The census form collects approximately 500 responses from each citizen. The agency needs to analyze the data to extract meaningful insights. The agency wants to reduce the dimensions of the high-dimensional data to uncover hidden patterns.
Which solution will meet these requirements?
An ML company wants to monitor and analyze the API calls that its AWS resources make. The company has created an AWS CloudTrail log file that logs to an Amazon S3 bucket. The company has also created an organization in AWS Organizations to manage permissions across accounts.
The company needs to enable log file validation to ensure the integrity of its log files.
Which solution will meet these requirements?
A gaming company needs to deploy a natural language processing (NLP) model to moderate a chat forum in a game. The workload experiences heavy usage during evenings and weekends but minimal activity during other hours.
Which solution will meet these requirements MOST cost-effectively?

TESTED 30 May 2026