Which of the following approaches is best if a limited portion of your training data is labeled?
Your dependent variable data is a proportion. The observed range of your data is 0.01 to 0.99. The instrument used to generate the dependent variable data is known to generate low quality data for values close to 0 and close to 1. A colleague suggests performing a logit-transformation on the data prior to performing a linear regression. Which of the following is a concern with this approach?
Definition of logit-transformation
If p is the proportion: logit(p)=log(p/(l-p))
Which of the following can take a question in natural language and return a precise answer to the question?
When should the model be retrained in the ML pipeline?
Which of the following unsupervised learning models can a bank use for fraud detection?
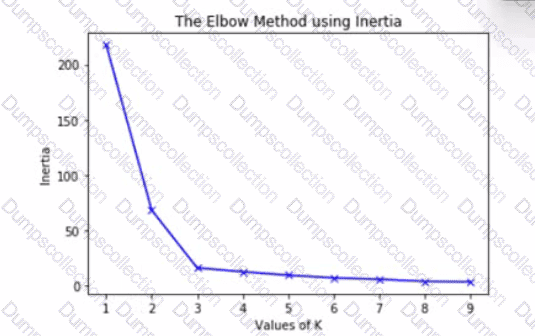
The graph is an elbow plot showing the inertia or within-cluster sum of squares on the y-axis and number of clusters (also called K) on the x-axis, denoting the change in inertia as the clusters change using k-means algorithm.
What would be an optimal value of K to ensure a good number of clusters?
Workflow design patterns for the machine learning pipelines:
An HR solutions firm is developing software for staffing agencies that uses machine learning.
The team uses training data to teach the algorithm and discovers that it generates lower employability scores for women. Also, it predicts that women, especially with children, are less likely to get a high-paying job.
Which type of bias has been discovered?
Which of the following equations best represent an LI norm?
Which of the following statements are true regarding highly interpretable models? (Select two.)

TESTED 27 Jul 2026