A Data Engineer enables a result cache at the session level with the following command:
ALTER SESSION SET USE CACHED RESULT = TRUE;
The Engineer then runs the following select query twice without delay:

The underlying table does not change between executions
What are the results of both runs?
What is a characteristic of the use of binding variables in JavaScript stored procedures in Snowflake?
A new customer table is created by a data pipeline in a Snowflake schema where MANAGED ACCESSenabled.
…. Can gran access to the CUSTOMER table? (Select THREE.)
A Data Engineer has created table t1 with datatype VARIANT:
create or replace table t1 (cl variant);
The Engineer has loaded the following JSON data set. which has information about 4 laptop models into the table:

The Engineer now wants to query that data set so that results are shown as normal structured data. The result should be 4 rows and 4 columns without the double quotes surrounding the data elements in the JSON data.
The result should be similar to the use case where the data was selected from a normal relational table z2 where t2 has string data type columns model__id. model, manufacturer, and =iccisi_r.an=. and is queried with the SQL clause select * from t2;
Which select command will produce the correct results?
A)

B)
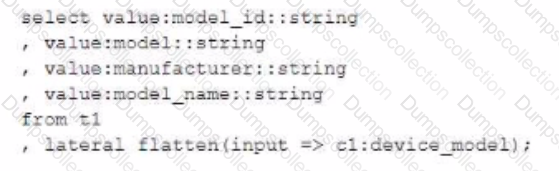
C)

D)
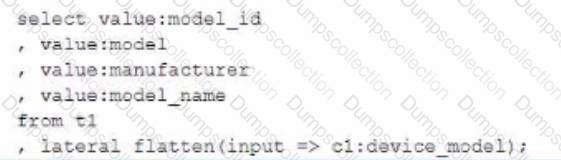
Database XYZ has the data_retention_time_in_days parameter set to 7 days and table xyz.public.ABC has the data_retention_time_in_daysset to 10 days.
A Developer accidentally dropped the database containing this single table 8 days ago and just discovered the mistake.
How can the table be recovered?
A company has an extensive script in Scala that transforms data by leveraging DataFrames. A Data engineer needs to move these transformations to Snowpark.
…characteristics of data transformations in Snowpark should be considered to meet this requirement? (Select TWO)
The following is returned fromSYSTEMCLUSTERING_INFORMATION () for a tablenamed orders with adate column named O_ORDERDATE:

What does the total_constant_partition_count value indicate about this table?
A stream called TRANSACTIONS_STM is created on top of a transactions table in a continuous pipeline running in Snowflake. After a couple of months, the TRANSACTIONS table is renamed transactiok3_raw to comply with new naming standards
What will happen to the TRANSACTIONS _STM object?
The JSON below is stored in a variant column named v in a table named jCustRaw:

Which query will return one row per team member (stored in the teamMembers array) along all of the attributes of each team member?
A)

B)
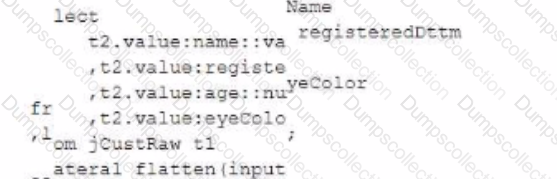
C)

D)

A CSV file around 1 TB in size is generated daily on an on-premise server A corresponding table. Internal stage, and file format have already been created in Snowflake to facilitate the data loading process
How can the process of bringing the CSV file into Snowflake be automated using the LEAST amount of operational overhead?

TESTED 19 Jul 2026